聚簇索引查看源代码讨论查看历史
 |
聚簇索引也叫簇类索引,是一种对磁盘上实际数据重新组织以按指定的一个或多个列的值排序。由于聚簇索引的索引页面指针指向数据页面,所以使用聚簇索引查找数据几乎总是比使用非聚簇索引快。每张表只能建一个聚簇索引,并且建聚簇索引需要至少相当该表120%的附加空间,以存放该表的副本和索引中间页。
简介
聚簇索引(Clustered Index)并不是一种单独的索引类型,而是一种数据存储方式。当表有了聚簇索引的时候,表的数据行都存放在索引树的叶子页中。
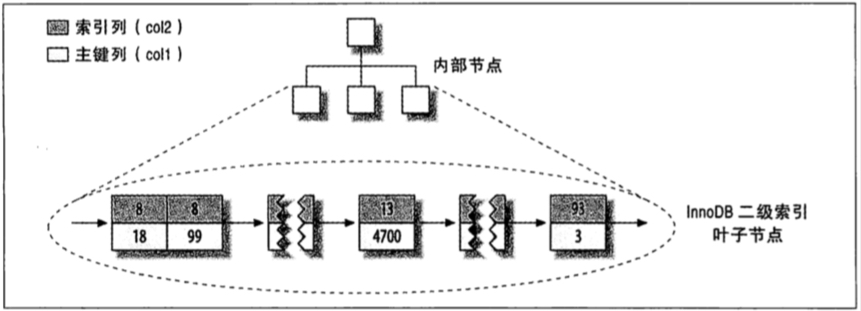
非聚簇索引(NoClustered Index),又叫二级索引。二级索引的叶子节点中保存的不是指向行的物理指针,而是行的主键值。
二、应用不同:
在《数据库原理》里面,对聚簇索引的解释是:聚簇索引的顺序就是数据的物理存储顺序,而对非聚簇索引的解释是:索引顺序与数据物理排列顺序无关。正式因为如此,所以一个表最多只能有一个聚簇索引。
在SQL Server中,索引是通过二叉树的数据结构来描述的,我们可以这么理解聚簇索引:索引的叶节点就是数据节点。而非聚簇索引的叶节点仍然是索引节点,只不过有一个指针指向对应的数据块。
特点介绍
聚簇索引也称为聚集索引,聚类索引,簇集索引,聚簇索引确定表中数据的物理顺序。聚簇索引类似于电话簿,后者按姓氏排列数据。由于聚簇索引规定数据在表中的物理存储顺序,因此一个表只能包含一个聚簇索引。但该索引可以包含多个列(组合索引),就像电话簿按姓氏和名字进行组织一样。汉语字典也是聚簇索引的典型应用,在汉语字典里,索引项是字母+声调,字典正文也是按照先字母再声调的顺序排列。
聚簇索引对于那些经常要搜索范围值的列特别有效。使用聚簇索引找到包含第一个值的行后,便可以确保包含后续索引值的行在物理相邻。例如,如果应用程序执行的一个查询经常检索某一日期范围内的记录,则使用聚集索引可以迅速找到包含开始日期的行,然后检索表中所有相邻的行,直到到达结束日期。这样有助于提高此类查询的性能。同样,如果对从表中检索的数据进行排序时经常要用到某一列,则可以将该表在该列上聚簇(物理排序),避免每次查询该列时都进行排序,从而节省成本。
思想
1、大多数表都应该有聚簇索引或使用分区来降低对表尾页的竞争,在一个高事务的环境中,对最后一页的封锁严重影响系统的吞吐量。
2、在聚簇索引下,数据在物理上按顺序排在数据页上,重复值也排在一起,因而在那些包含范围检查(between、<、<=、>、>=)或使用group by或orderby的查询时,一旦找到具有范围中第一个键值的行,具有后续索引值的行保证物理上毗连在一起而不必进一步搜索,避免了大范围扫描,可以大大提高查询速度。
3、在一个频繁发生插入操作的表上建立聚簇索引时,不要建在具有单调上升值的列(如IDENTITY)上,否则会经常引起封锁冲突。
4、在聚簇索引中不要包含经常修改的列,因为码值修改后,数据行必须移动到新的位置。
5、选择聚簇索引应基于where子句和连接操作的类型。
候选列
2、按范围存取的列,如pri_order>100 and pri_order<200。
3、在group by或order by中使用的列。
4、不经常修改的列。
5、在连接操作中使用的列。
聚簇索引表
聚簇是指:如果一组表有一些共同的列,则将这样一组表存储在相同的数据库块中;聚簇还表示把相关的数据存储在同一个块上。利用聚簇,一个块可能包含多个表的数据。概念上就是如果两个或多个表经常做链接操作,那么可以把需要的数据预先存储在一起。聚簇还可以用于单个表,可以按某个列将数据分组存储。
更加简单的说,比如说,EMP表和DEPT表,这两个表存储在不同的segment中,甚至有可能存储在不同的TABLESPACE中,因此,他们的数据一定不会在同一个BLOCK里。而我们又会经常对这两个表做关联查询,比如说:select * from emp,dept where emp.deptno = dept.deptno .仔细想想,查询主要是对BLOCK的操作,查询的BLOCK越多,系统IO就消耗越大。如果我把这两个表的数据聚集在少量的BLOCK里,查询效率一定会提高不少。
比如我将值deptno=10的所有员工抽取出来,并且把对应的部门信息也存储在这个BLOCK里(如果存不下了,可以为原来的块串联另外的块)。这就是索引聚簇表的工作原理。 [1]
视频
聚簇索引就是主键索引吗?